

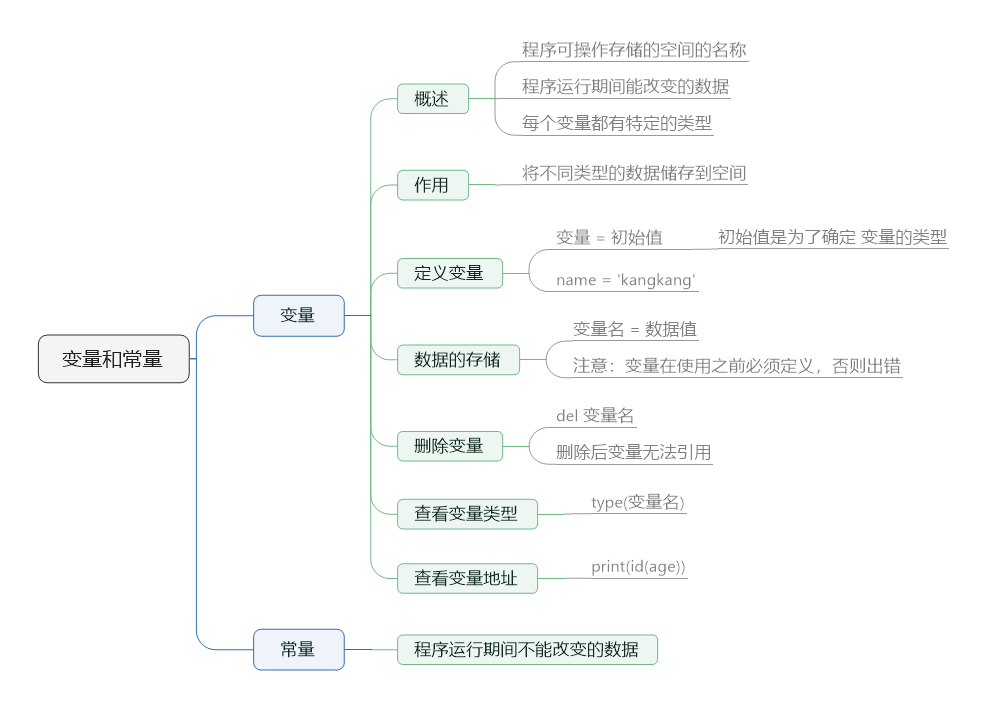
2.1. 标识符、变量与常量
标识符:开发人员在程序中自定义的一些符合和名称,其实就是一串字符串,如变量名、函数名等
Python标识符规则:只能由数字、字符和下划线组成,开头不能是数字,不能是关键字,大小写敏感且见名知义,要遵循小驼峰原则。

1 | import keyword |
变量:在程序运行过程中,其值可以改变的量。
变量命名原则:尽量做到见名知意、尽量使用英文、推荐使用全小写加下划线的方式,如user_name
常量:程序运行期间不会改变的数据,如a = 1。在python中没有常量,通常使用大写字母加下划线的方式模拟,如:USER_NAME = 'xiaoming'
代码注释:单行注释(# 注释内容)、多行注释('''注释''', """注释""")
2.2. 数据类型
数据类型是为了处理不同的运算而存在,python中的数据类型有:整型(int)、浮点(float)、字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)、空(NoneType)
2.2.1. 字符串格式化
在 Python 3.6 之前,字符串格式化方法主要有两种:%格式化 和 str.format(),Python3.6提供了一种新的字符串格式化方法:f-string
(1)
%-格式化从 Python 刚开始时就存在了,堪称「一届元老」,但是 Python 官方文档中并不推荐这种格式化方式:这里描述的格式化操作容易表现出各种问题,导致许多常见错误(例如无法正确显示元组和字典)。 使用较新的格式化字符串文字或 str.format() 可以有助于避免这些错误。这些替代方案还提供了更强大,灵活和可扩展的格式化文本方法。
1
2
3
4name = 'lajos'
age = 18
'hello, %s, your age is %s ?' %(name, age)
'hello, lajos, your age is 18?'(2)
str.formar()从Python2.6开始引入,它使用普通函数调用语法,并且可以通过__format__()方法为对象进行扩展。1
2"hello, {}. you are {}?".format(name,age)
'hello, hoxis. you are 18?'1
2"hello, {1}. you are {0}?".format(age,name)
'hello, hoxis. you are 18?'1
2"hello, {name}. you are {age1}?".format(age1=age,name=name)
'hello, hoxis. you are 18?'1
2
3person = {"name":"hoxis","age":18}
"hello, {name}. you are {age}?".format(**person)
'hello, hoxis. you are 18?'(3)
f-Strings是指以f或F开头的字符串,其中以{}包含的表达式会进行值替换。f-string 里的 f 也许可以代表fast,它比 %格式化方法和 str.format() 都要快:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41name = 'hoxis'
age = 18
f"hi, {name}, are you {age}" # 替换字符串
'hi, hoxis, are you 18'
F"hi, {name}, are you {age}"
'hi, hoxis, are you 18'
f"{name.lower()} is handsome." # 调用函数
'hoxis is handsome.'
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return f"{self.name} is {self.age}" # 在类中使用
def __repr__(self):
return f"{self.name} is {self.age}. HAHA!"
...
hoxis = Person("hoxis",18)
f"{hoxis}"
'hoxis is 18'
f"{hoxis!r}"
'hoxis is 18. HAHA!'
print(hoxis)
hoxis is 18
hoxis
hoxis is 18. HAHA!
name = 'hoxis'
age = 18
status = 'Python'
message = {
f'hi {name}.'
f'you are {age}.'
f'you are learning {status}.'
} # 多行f-string
>>>
message
{'hi hoxis.you are 18.you are learning Python.'}
(4)f-string在python3.8中加入新特性,可以在表达式的末尾添加=,此时可以同时显示表达式和值
1 | >>> python = 3.8 |
2.2.2. 列表、元组、字典、集合的区别
| 特点 | |
|---|---|
| 列表 | 列表是一组任意类型的值,按照一定的顺序组合而成; 通过索引来标识元素,第一个索引为0;需要注意的是索引可以是负值; 3列表中元素是任意类型的,包括列表类型; 可以进行合并,删除,索引,切片等操作; 5 定义表使用中括号。 |
| 元组 | 元组是任意对象的有序集合(这一点和列表相同); 元组是不可变的(不能 增,删,改),但可以对元组进行合并; 元组的速度比列表要快; 定义元组使用小括号; 需要注意的是定义一个元素时需要加上逗号,例如tuple=(333,)。 |
| 字典 | 字典是通过键值对进行存储的,所以字典没有顺序; 字典是通过键值进行索引的且键值必须唯一; 字典可以进行增,删,改,查等操作,可以包含任意其他类型; 定义字典使用大括号,各个键值对之间使用逗号隔开。 |
| 集合 | 集合是简单对象的无序不重复元素集合; 集合分为可变集合set(元素是可哈希的),不可变集合frozenset(元素不可哈希); 可以进行去除重复元素; 可以进行并集,交集,差集等。 |
字典的创建方法:
直接创建:
dict = {'name': 'earth', 'port': 80}1
2
3
4
5
6
7class dict(**kwarg) # **kwargs -- 关键字
class dict(mapping, **kwarg) # mapping -- 元素的容器。
class dict(iterable, **kwarg) # iterable -- 可迭代对象。
dict1 = {"a": 1, "b": 2}
dict2 = {"c": 3}
dict3 = dict(dict1, **dict2) # dict3 = {"a": 1, "b": 2, "c": 3}工厂方法:
1
2
3items = [('name', 'earth'), ('port', 80)]
dict1 = dict(items)
dict2 = dict((['name', 'earth'], ['port', '80']))fromkeys()方法1
2dict1 = {}.fromkeys(('x', 'y'), -1) # {'x': -1, 'y': -1}
dict2 = {}.fromkeys(('x', 'y')) # {'x': None, 'y': None}
2.3. 运算符与流程控制
2.3.1. 运算符

运算符优先级:无需记录运算符的优先级,需要的时候添加()即可。
灵活的or:a = False or 2, 赋值前会判断前面的值,若为真则使用,若为假,则使用or后面的值
海象表达式:=:python3.8引入的新语法,将给变量赋值,这个变量可以是表达式的一部分。
1 | # 用在if中可以避免调用len()两次 |
2.3.2. 流程控制

列表生成式:
1 | print([i for i in range(1, 11)]) |
冒泡排序法:每次比较相邻的两个元素,不合适就交换,依次向后,一圈下来可以确定一个元素;需要使用双重循环,外层循环控制循环的圈数, 内层控制一圈怎么交换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def bubble_sort(lt, key=None, reverse=False):
for i in range(len(lt) - 1):
for j in range(len(lt) - 1 - i):
if key == None:
temp = lt[i] <= lt[i + 1] if reverse else lt[i] > lt[i + 1]
else:
temp = key(lt[i]) <= lt[i + 1] if reverse else key(lt[i]) > key(lt[i + 1])
if temp:
lt[i], lt[i + 1] = lt[i + 1], lt[i]
print(lt)
lt1 = [1, 5, 2, 1, 4, 9]
lt2 = [
{'name': 'xiaoming', 'age': 12, 'height': 160},
{'name': 'xiaohua', 'age': 17, 'height': 140},
{'name': 'xiaogang', 'age': 11, 'height': 180}
]
choose_sort(lt1)
choose_sort(lt2, key=lamamb x: x['age'])选择排序法:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def choose_sort(lt, key=None, reverse=False):
for i in range(len(lt) - 1):
for j in range(i + 1, len(lt)):
if key == None:
temp = lt[i] <= lt[j] if reverse else lt[i] > lt [j]
else:
temp = key(lt[i]) <= key(lt[j]) if reverse else key(lt[i]) > key(lt[j])
if temp:
lt[i], lt[j] = lt[j], lt[i]
print(lt)
lt1 = [1, 5, 2, 1, 4, 9]
lt2 = [
{'name': 'xiaoming', 'age': 12, 'height': 160},
{'name': 'xiaohua', 'age': 17, 'height': 140},
{'name': 'xiaogang', 'age': 11, 'height': 180}
]
choose_sort(lt1)
choose_sort(lt2, key=lamamb x: x['age'])


- 本文作者: Lajos
- 本文链接: https://www.lajos.top/2020/04/27/No-2-Python语言基础-变量、数据类型及运算符/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!